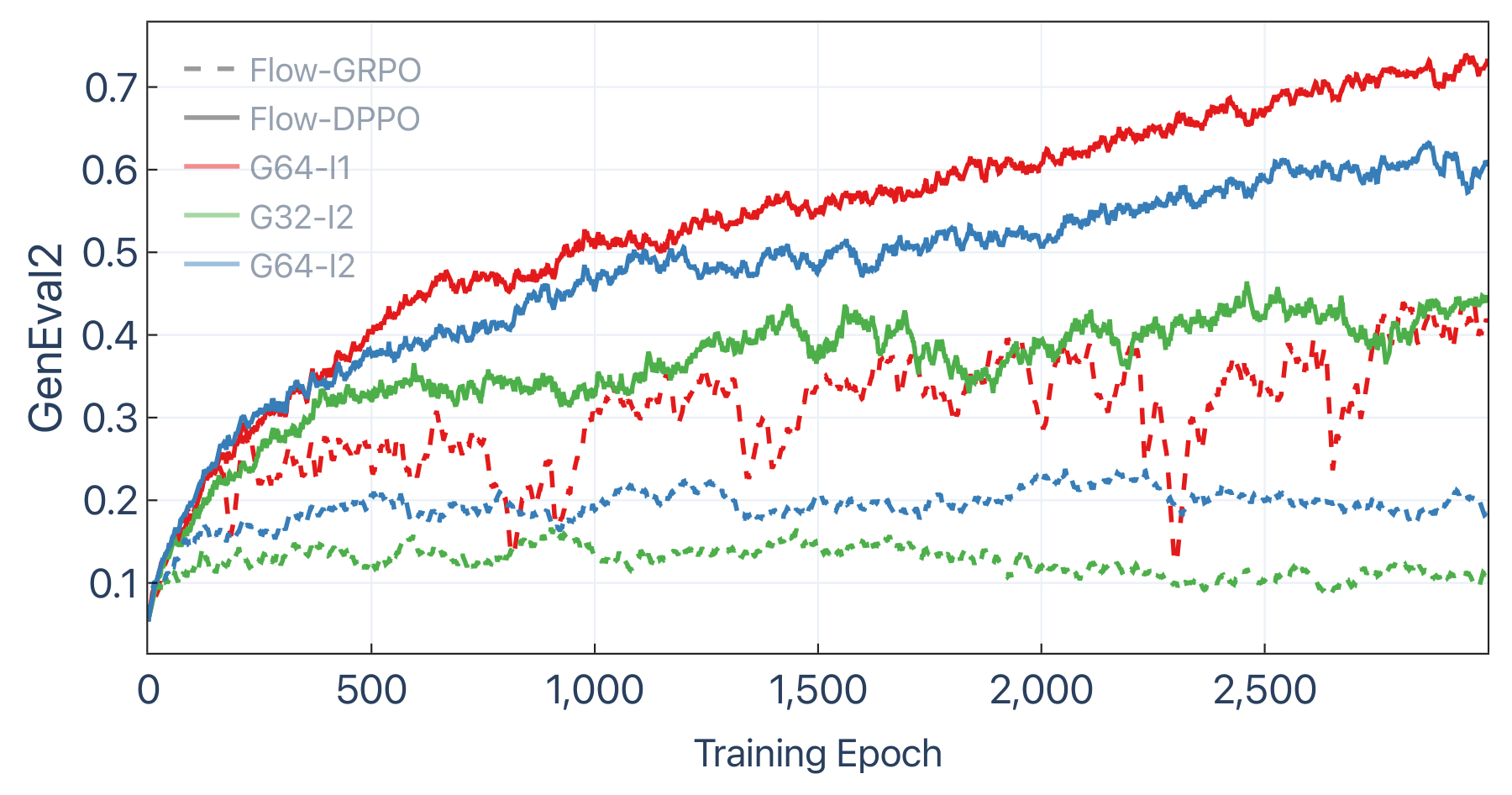
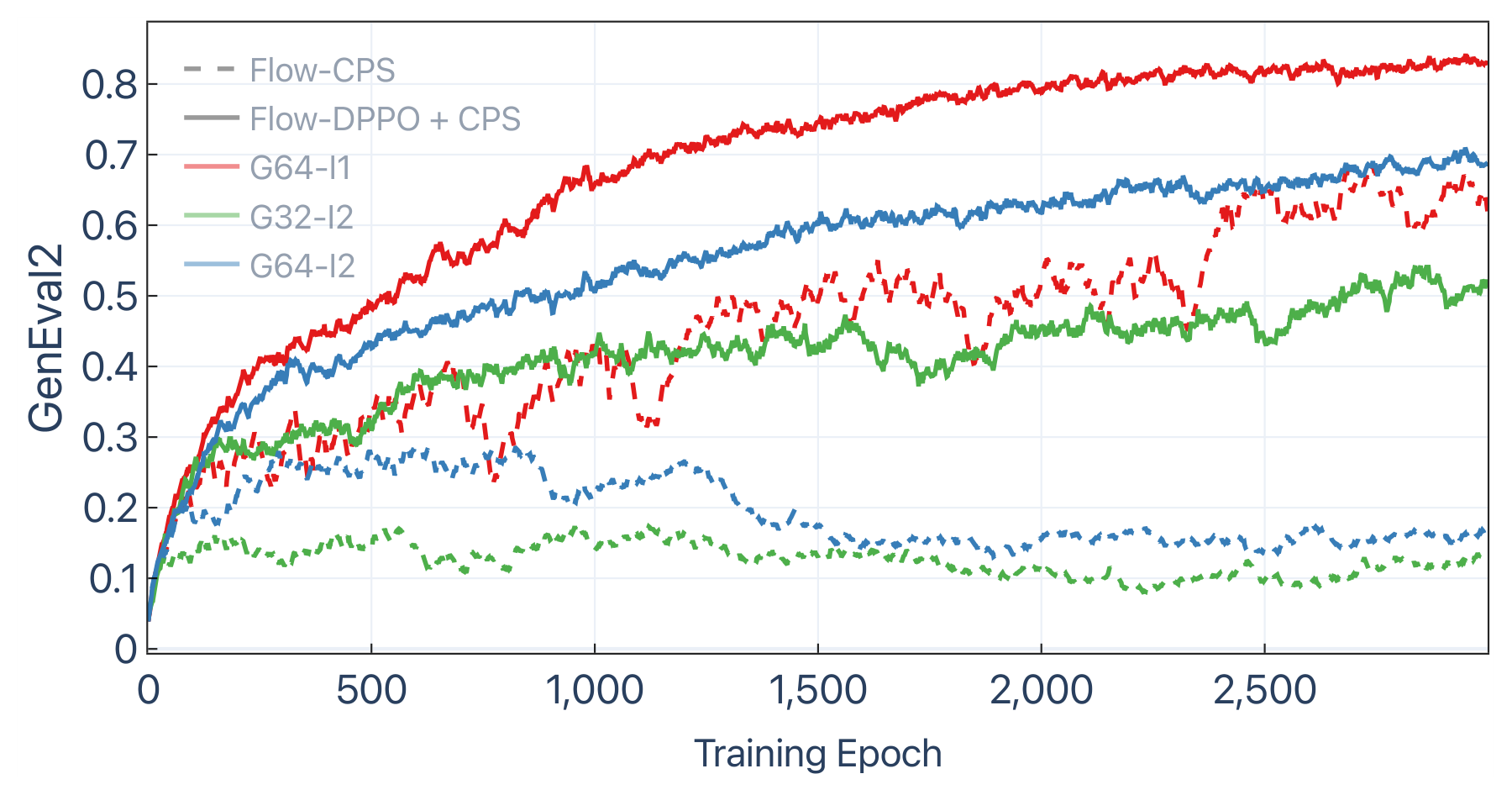
Performance comparison under multi-reward RL fine-tuning (GDPO with equal weights). Bold = best, underline = second best.
| In-Domain (GenEval2) | Out-of-Domain (PickScore) | ||||||
|---|---|---|---|---|---|---|---|
| Method | GenEval2 ↑ | CLIP ↑ | PickScore ↑ | HPSv2 ↑ | CLIP ↑ | PickScore ↑ | HPSv2 ↑ |
| SD3.5-medium (pretrained: GenEval2 12.4) | |||||||
| Flow-GRPO | 39.9 | 0.358 | 25.09 | 0.399 | 0.273 | 22.07 | 0.349 |
| Flow-CPS | 44.6 | 0.359 | 25.51 | 0.407 | 0.265 | 22.08 | 0.343 |
| GRPO-Guard | 47.8 | 0.353 | 25.64 | 0.409 | 0.272 | 22.32 | 0.354 |
| Diffusion-NFT | 42.5 | 0.334 | 25.30 | 0.394 | 0.269 | 22.52 | 0.355 |
| Flow-DPPO | 48.1 | 0.345 | 25.63 | 0.409 | 0.273 | 22.58 | 0.360 |
| Flow-DPPO + CPS | 51.6 | 0.369 | 25.72 | 0.415 | 0.279 | 22.51 | 0.361 |
| FLUX2-klein-base-9B (pretrained: GenEval2 25.4) | |||||||
| Flow-GRPO | 46.8 | 0.371 | 25.61 | 0.412 | 0.277 | 22.62 | 0.357 |
| Flow-CPS | 47.1 | 0.361 | 25.70 | 0.416 | 0.276 | 22.85 | 0.364 |
| GRPO-Guard | 49.0 | 0.375 | 25.27 | 0.411 | 0.269 | 21.99 | 0.349 |
| Diffusion-NFT | 47.3 | 0.336 | 24.87 | 0.389 | 0.274 | 22.47 | 0.351 |
| Flow-DPPO | 57.7 | 0.364 | 25.76 | 0.418 | 0.282 | 22.90 | 0.368 |
| Flow-DPPO + CPS | 55.2 | 0.386 | 26.15 | 0.427 | 0.287 | 22.97 | 0.370 |